前言
Redis的“数据结构”,可以划分为两个不同的层面。第一个层面是从使用者的角度,比如:
- string
- list
- hash
- set
- sorted set
这一层面也是Redis暴露给外部的调用接口。
第二个层面,是从内部实现的角度,属于更底层的实现。比如:
- dict
- sds
- ziplist
- quicklist
- skiplist
接下来将开一个系列详细解析Redis内部数据结构的实现,首先从动态字符串SDS开始。
动态字符串SDS
简介
Redis中保存的Key是字符串,value往往是字符串或者字符串的集合。可见字符串是Redis中最常用的一种数据结构。Redis并没有采用C语言的字符串实现,因为其具有以下不足:
- 获取字符串长度需要通过运算;
- 非二进制安全,即无法保存’\0’;
- 不可修改;
Redis构建了一种新的字符串结构用于解决C语言字符串的不足,称为简单动态字符串(Simple Dynamic String),简称SDS。
具体实现
基本结构
SDS结构体源码如下,共有5种类型的header。之所以有5种,是为了能让不同长度的字符串可以使用不同大小的header。这样,短字符串就能使用较小的header,从而节省内存:
1 | struct __attribute__ ((__packed__)) sdshdr8 { |
例如,一个包含字符串“name”的sds结构如下:
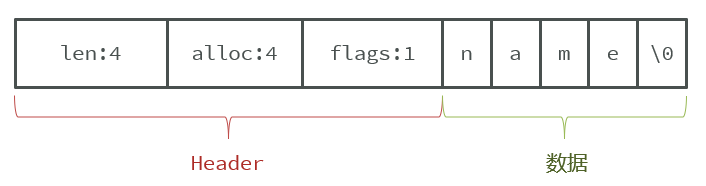
注意到结构体定义中使用了_attribute_ ((__packed__))属性,在是为了让编译器以紧凑模式来分配内存,从而保证可以直接通过地址值偏移找到header中的字段,以及buf数组中对应的数据。
动态内存管理
SDS 提供了动态内存管理功能,可以自动扩展和收缩内存,避免了传统 C 字符串常见的内存溢出和内存浪费问题。
-
自动扩展:当字符串分配到的内存不足,需要扩展时,SDS 会自动分配更大的内存空间,并复制原有内容。具体策略如下:
- 如果字符串长度小于 1MB,SDS 会分配两倍于当前长度的空间。
- 如果字符串长度大于 1MB,SDS 会额外分配 1MB 的空间。
SDS 分配比当前长度更多的空间的目的是减少后续的内存分配次数。
-
内存收缩:当字符串缩短时,SDS 会自动释放多余的内存。SDS 采用惰性空间释放机制,不会立即释放多余的空间,而是保留这些空间以供后续使用。这可以避免频繁的内存分配和释放操作。
避免内存拷贝
SDS 在某些操作中可以避免不必要的内存拷贝,提高性能。SDS 提供了 sdscatlen 函数,可以直接在原字符串后面追加内容,而不需要重新分配内存。
1 | sds sdscatlen(sds s, const void *t, size_t len) { |
Value类型的底层就是SDS吗?
虽然 Redis 的 String (Value)类型的值底层是 SDS,但在处理数值操作(如 INCR、DECR、INCRBY、DECRBY 等)时,Redis 会将字符串值解析为数值,执行数值操作后再将结果转换回字符串存储。这种操作并不是直接通过 SDS 的字符串操作功能实现的,而是通过标准的数值解析和操作完成的。
__END__
