SPI机制
简介
SPI(Service Provider Interface)是一种服务提供者接口机制,用于实现插件式架构。SPI 允许开发者定义接口,并通过配置文件动态加载实现类。相比API( Application Programming Interface),他们的不同之处在于API是应用提供给外部的功能,而SPI则更倾向于是规定好规范,具体实现由使用方自行实现。
以JDBC为例
JDBC 使用 SPI 机制来加载和管理数据库驱动程序,从而实现与不同数据库的连接和交互。
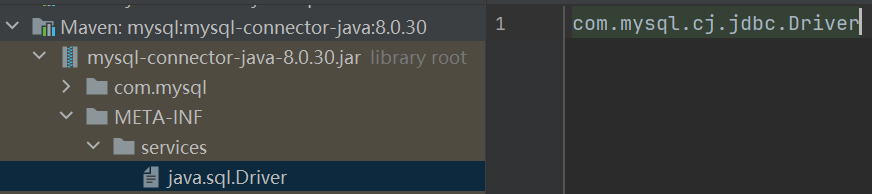
具体来说,JDBC 定义了一个 Driver 接口,而各个数据库厂商提供了该接口的具体实现。JDBC 使用 ServiceLoader 来动态加载这些驱动程序。数据库驱动程序需要在 META-INF/services 目录下提供一个配置文件,文件名为 java.sql.Driver。文件内容为实现类的全限定名,以MySQL为例,有图有真相:
JDK SPI
使用示例
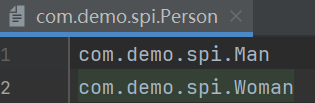
定义一个接口和两个实现类,并在resources/META-INF/services目录下新建一个以接口名为文件名,实现类为文件内容的文件,整体结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public interface Person { void say () ; } public class Man implements Person { @Override public void say () { System.out.println("I am man" ); } } public class Woman implements Person { @Override public void say () { System.out.println("I am Woman" ); } } public class SpiTest { public static void main (String[] args) { ServiceLoader<Person> loaded = ServiceLoader.load(Person.class); Iterator<Person> iterator = loaded.iterator(); while (iterator.hasNext()){ Person person = iterator.next(); person.say(); } } }
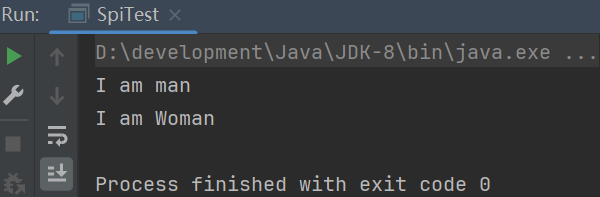
执行结果如下:
源码分析
注意,此处使用JDK8 的源码来进行分析,因为JDK9之后引入了module机制导致这部分代码为了兼容module也进行了大改,变得更为复杂不利于理解。
ServiceLoader的成员变量如下,其中最重要的是providers,一个缓存搜索结果的map和lookupIterator,用来搜索指定类的自定义迭代器。另外还定义了SPI的默认搜索路径PREFIX。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private static final String PREFIX = "META-INF/services/" ;private final Class<S> service;private final ClassLoader loader;private final AccessControlContext acc;private LinkedHashMap<String,S> providers = new LinkedHashMap <>();private LazyIterator lookupIterator;
首先从ServiceLoader.load()进入:
1 2 3 4 5 6 7 8 9 10 public static <S> ServiceLoader<S> load (Class<S> service) { ClassLoader cl = Thread.currentThread().getContextClassLoader(); return ServiceLoader.load(service, cl); } public static <S> ServiceLoader<S> load (Class<S> service, ClassLoader loader) { return new ServiceLoader <>(service, loader); }
其实就是找当前线程绑定的 ClassLoader,如果没有就用 SystemClassLoader,然后将接口类和ClassLoader传入构造函数。接下来看构造函数:
1 2 3 4 5 6 7 8 9 10 11 private ServiceLoader (Class<S> svc, ClassLoader cl) { service = Objects.requireNonNull(svc, "Service interface cannot be null" ); loader = (cl == null ) ? ClassLoader.getSystemClassLoader() : cl; acc = (System.getSecurityManager() != null ) ? AccessController.getContext() : null ; reload(); } public void reload () { providers.clear(); lookupIterator = new LazyIterator (service, loader); }
构造函数内做的事主要是清除一下缓存,然后创建一个 LazyIterator赋值给lookupIterator。所以接下来重点就是 LazyIterator,它其实是Iterator的实现类,因此我们来看它的hasNext和next方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public boolean hasNext () { if (acc == null ) { return hasNextService(); } else { PrivilegedAction<Boolean> action = new PrivilegedAction <Boolean>() { public Boolean run () { return hasNextService(); } }; return AccessController.doPrivileged(action, acc); } } public S next () { if (acc == null ) { return nextService(); } else { PrivilegedAction<S> action = new PrivilegedAction <S>() { public S run () { return nextService(); } }; return AccessController.doPrivileged(action, acc); } }
可以发现无论是if还是else分支,hasNext都返回了hasNextService()的结果,next都返回了nextService()的结果。因此下面看这两个函数,也是ServiceLoader的核心逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 private boolean hasNextService () { if (nextName != null ) { return true ; } if (configs == null ) { try { String fullName = PREFIX + service.getName(); if (loader == null ) configs = ClassLoader.getSystemResources(fullName); else configs = loader.getResources(fullName); } catch (IOException x) { fail(service, "Error locating configuration files" , x); } } while ((pending == null ) || !pending.hasNext()) { if (!configs.hasMoreElements()) { return false ; } pending = parse(service, configs.nextElement()); } nextName = pending.next(); return true ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 private S nextService () { if (!hasNextService()) throw new NoSuchElementException (); String cn = nextName; nextName = null ; Class<?> c = null ; try { c = Class.forName(cn, false , loader); } catch (ClassNotFoundException x) { fail(service, "Provider " + cn + " not found" ); } if (!service.isAssignableFrom(c)) { fail(service, "Provider " + cn + " not a subtype" ); } try { S p = service.cast(c.getDeclaredConstructor().newInstance()); providers.put(cn, p); return p; } catch (Throwable x) { fail(service, "Provider " + cn + " could not be instantiated" , x); } throw new Error (); }
这两个函数就说明了SPI机制的核心思路:从约定好的文件路径下读取配置文件,解析文件生成一个存储了服务提供者类名的迭代器pending,每次调用next就从这个迭代器取出下一个类名并实例化。
接下来,在调用ServiceLoader的iterator()方法时,就会从lookupIterator即lazyIterator中迭代获取服务提供者实现类,边获取边将它们加入providers缓存中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public Iterator<S> iterator () { return new Iterator <S>() { Iterator<Map.Entry<String, S>> knownProviders = providers.entrySet().iterator(); public boolean hasNext () { if (knownProviders.hasNext()) return true ; return lookupIterator.hasNext(); } public S next () { if (knownProviders.hasNext()) return knownProviders.next().getValue(); return lookupIterator.next(); } public void remove () { throw new UnsupportedOperationException (); } }; }
这里也能看出来lazyIterator 中“lazy”的含义:在真正遍历到一个服务提供者时才会实例化它。
劣势
如果配置文件中有多个服务提供者,即便我们只需要其中一个,ServiceLoader 还是需要逐个加载和实例化这些类,即无法实现按需加载 。并且只要其中一个加载失败,ServiceLoader 会直接抛出异常,而不是继续加载其他提供者。
Dubbo SPI
介绍
为了解决按需加载问题,Dubbo自己也实现了一个SPI。与Java SPI不同,它包含三个目录:
META-INF/services/ 目录:该目录下的 SPI 配置文件是为了用来兼容 Java SPI 。
META-INF/dubbo/ 目录:该目录存放用户自定义的 SPI 配置文件。
META-INF/dubbo/internal/ 目录:该目录存放 Dubbo 内部使用的 SPI 配置文件。
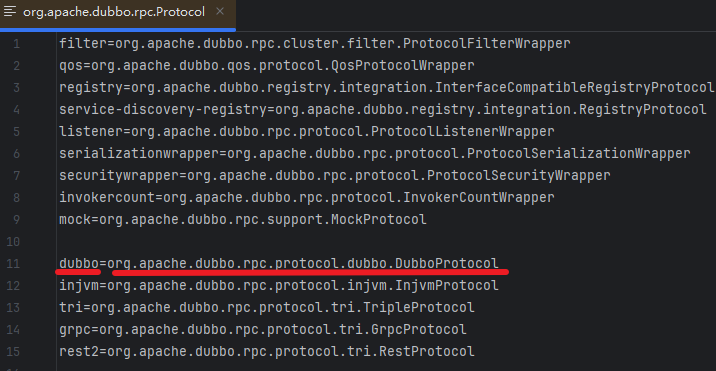
Dubbo SPI机制同样是以接口全限定名作为文件名,但文件内容发生了改变,将实现类全限定名集合改为了键值对,其中value仍然为实现类名,而key则是实现类的唯一标识,这种设计允许使用者通过指定key来按需加载特定的实现类,避免了不必要的资源消耗,提高了系统的灵活性和性能。以Protocol接口为例,看一下配置文件:
Dubbo SPI使用示例
接下来用一个简单的例子学习Dubbo SPI的使用方式。首先在用户自定义SPI目录即META-INF/dubbo下新建一个配置文件:
接口和实现类代码如下,注意要想开启Dubbo SPI,需要在接口上标注@SPI注解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @SPI("good") public interface Robot { void sayHello () ; } public class GoodRobot implements Robot { public void sayHello () { System.out.println("GoodRobot say hello" ); } } public class BrokenRobot implements Robot { public void sayHello () { System.out.println("I *a@m *bro/k*en" ); } }
接着可以通过下面这个小例子加载默认实现类或者指定的实现类:
1 2 3 4 5 6 7 8 9 public class SpiTest { public static void main (String[] args) { ExtensionLoader<Robot> extensionLoader = ExtensionLoader.getExtensionLoader(Robot.class); Robot robot = extensionLoader.getDefaultExtension(); robot.sayHello(); robot = extensionLoader.getExtension("broken" ); robot.sayHello(); } }
控制台输出结果符合预期:
1 2 GoodRobot say hello I *a@m *bro/k*en
Dubbo SPI源码分析
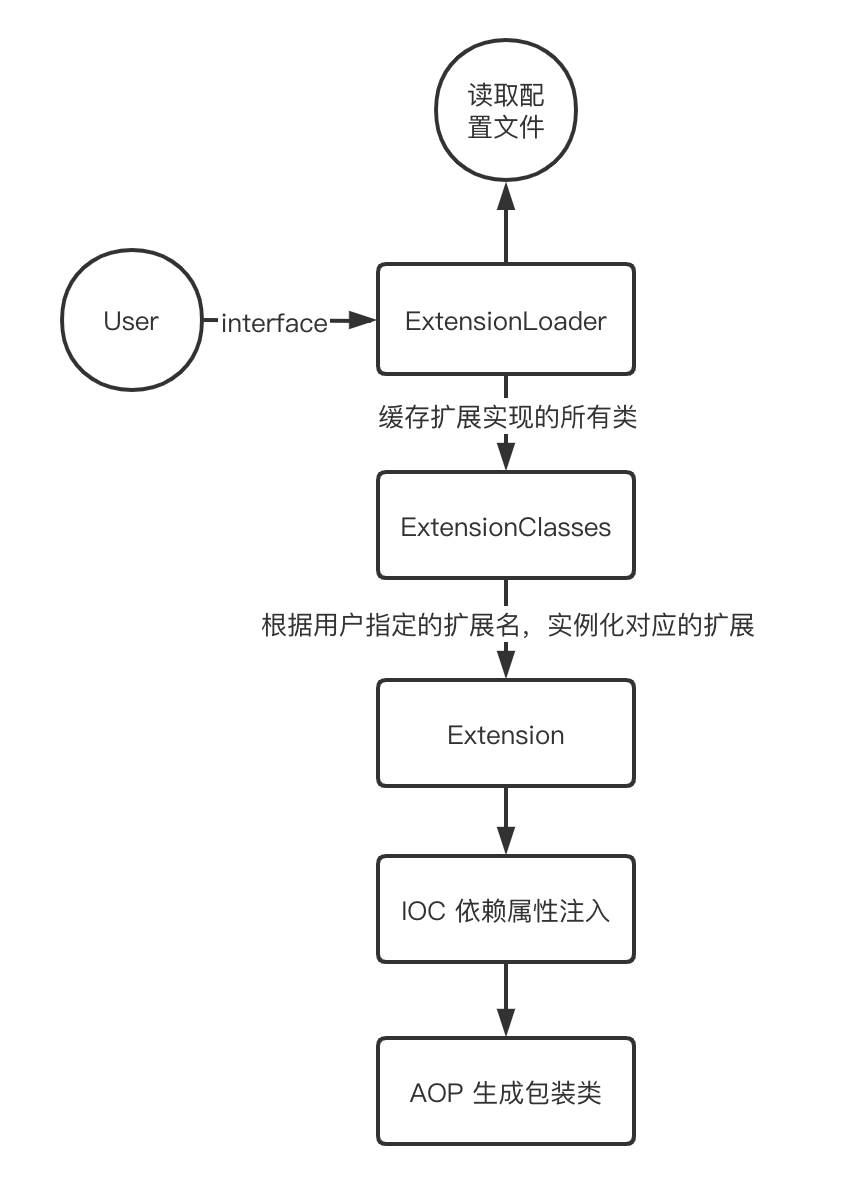
说明:本文章基于Dubbo3.3.0进行源码分析。加载扩展的整个流程如下图:
getExtension()方法
Dubbo 3版本引入了模块领域模型,因此直接调用ExtensionLoader.getExtensionLoader()实际上是会报方法弃用警告的,如下所示:
1 2 3 4 @Deprecated public static <T> ExtensionLoader<T> getExtensionLoader (Class<T> type) { return ApplicationModel.defaultModel().getDefaultModule().getExtensionLoader(type); }
关于模块领域模型这个概念,我们先按下不表,重点关注SPI机制的实现,getExtensionLoader()的关键源码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 private final ConcurrentMap<Class<?>, ExtensionLoader<?>> extensionLoadersMap = new ConcurrentHashMap (64 );public <T> ExtensionLoader<T> getExtensionLoader (Class<T> type) { ExtensionLoader<T> loader = (ExtensionLoader)this .extensionLoadersMap.get(type); if (loader == null ) { loader = this .createExtensionLoader(type); } return loader; } private <T> ExtensionLoader<T> createExtensionLoader (Class<T> type) { ExtensionLoader<T> loader = null ; if (this .isScopeMatched(type)) { loader = this .createExtensionLoader0(type); } return loader; } private <T> ExtensionLoader<T> createExtensionLoader0 (Class<T> type) { this .checkDestroyed(); this .extensionLoadersMap.putIfAbsent(type, new ExtensionLoader (type, this , this .scopeModel)); ExtensionLoader<T> loader = (ExtensionLoader)this .extensionLoadersMap.get(type); return loader; }
其实就是从缓存里面找是否已经存在这个类型对应的 ExtensionLoader ,如果没有就新建一个塞入缓存。最后返回接口类对应的 ExtensionLoader 。
接下来看一下 getExtension() 方法,从现象我们可以知道这个方法就是从类对应的 ExtensionLoader 中通过名字找到实例化完的实现类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public T getExtension (String name) { T extension = this .getExtension(name, true ); if (extension == null ) { throw new IllegalArgumentException ("Not find extension: " + name); } else { return extension; } } public T getExtension (String name, boolean wrap) { this .checkDestroyed(); if (StringUtils.isEmpty(name)) { throw new IllegalArgumentException ("Extension name == null" ); } else if ("true" .equals(name)) { return this .getDefaultExtension(); } else { String cacheKey = name; if (!wrap) { cacheKey = cacheKey + "_origin" ; } Holder<Object> holder = this .getOrCreateHolder(cacheKey); Object instance = holder.get(); if (instance == null ) { synchronized (holder) { instance = holder.get(); if (instance == null ) { instance = this .createExtension(name, wrap); holder.set(instance); } } } return instance; } }
重点是调用 createExtension 方法,创建扩展实例, createExtension()代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 private T createExtension (String name, boolean wrap) { Class<?> clazz = (Class)this .getExtensionClasses().get(name); if (clazz != null && !this .unacceptableExceptions.contains(name)) { try { T instance = this .extensionInstances.get(clazz); if (instance == null ) { this .extensionInstances.putIfAbsent(clazz, this .createExtensionInstance(clazz)); instance = this .extensionInstances.get(clazz); instance = this .postProcessBeforeInitialization(instance, name); this .injectExtension(instance); instance = this .postProcessAfterInitialization(instance, name); } if (wrap) { List<Class<?>> wrapperClassesList = new ArrayList (); if (this .cachedWrapperClasses != null ) { wrapperClassesList.addAll(this .cachedWrapperClasses); wrapperClassesList.sort(WrapperComparator.COMPARATOR); Collections.reverse(wrapperClassesList); } if (CollectionUtils.isNotEmpty(wrapperClassesList)) { Iterator var6 = wrapperClassesList.iterator(); while (var6.hasNext()) { Class<?> wrapperClass = (Class)var6.next(); Wrapper wrapper = (Wrapper)wrapperClass.getAnnotation(Wrapper.class); boolean match = wrapper == null || (ArrayUtils.isEmpty(wrapper.matches()) || ArrayUtils.contains(wrapper.matches(), name)) && !ArrayUtils.contains(wrapper.mismatches(), name); if (match) { instance = this .injectExtension(wrapperClass.getConstructor(this .type).newInstance(instance)); instance = this .postProcessAfterInitialization(instance, name); } } } } this .initExtension(instance); return instance; } catch (Throwable var10) { } } else { throw this .findException(name); } }
小小总结一下getExtension的整个流程:
通过类名得到一个ExtensionLoader;
通过唯一标识去ExtensionLoader中找到实现类的实例,如果缓存中没有就调用createExtension创建实例;
在createExtension方法中:
通过 getExtensionClasses 获取所有的拓展类
通过反射创建拓展对象
向拓展对象中注入依赖
将拓展对象包裹在相应的 Wrapper 对象中
初始化拓展对象
getExtensionClasses()方法
该方法的作用是指定扩展点的所有扩展类的映射,通俗来说就是返回一个哈希表,Entry为某个接口的所有 { 自定义key->实现类名 } 。其中采用了双检锁机制和缓存思想进行扩展类映射的读取,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 private Map<String, Class<?>> getExtensionClasses() { Map<String, Class<?>> classes = (Map)this .cachedClasses.get(); if (classes == null ) { this .loadExtensionClassesLock.lock(); try { classes = (Map)this .cachedClasses.get(); if (classes == null ) { try { classes = this .loadExtensionClasses(); } catch (InterruptedException var6) { } this .cachedClasses.set(classes); } } finally { this .loadExtensionClassesLock.unlock(); } } return classes; }
loadExtensionClasses()方法
可以发现在双检锁的最内部又调用了loadExtensionClasses加载扩展类映射,这个方法的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 private Map<String, Class<?>> loadExtensionClasses() throws InterruptedException { this .checkDestroyed(); this .cacheDefaultExtensionName(); Map<String, Class<?>> extensionClasses = new HashMap (); LoadingStrategy[] var2 = strategies; int var3 = var2.length; for (int var4 = 0 ; var4 < var3; ++var4) { LoadingStrategy strategy = var2[var4]; this .loadDirectory(extensionClasses, strategy, this .type.getName()); if (this .type == ExtensionInjector.class) { this .loadDirectory(extensionClasses, strategy, ExtensionFactory.class.getName()); } } return extensionClasses; } private void loadDirectory (Map<String, Class<?>> extensionClasses, LoadingStrategy strategy, String type) throws InterruptedException { this .loadDirectoryInternal(extensionClasses, strategy, type); if (Dubbo2CompactUtils.isEnabled()) { } }
那么加载时究竟是怎么找到配置文件目录的呢?这与LoadingStrategy加载策略有关:
DubboInternalLoadingStrategy:从 META - INF/dubbo/internal目录下加载扩展类的配置信息。DubboLoadingStrategy:从META - INF/dubbo 目录下加载扩展类的配置信息。ServicesLoadingStrategy:从 META - INF/services 目录下加载扩展类的配置信息。
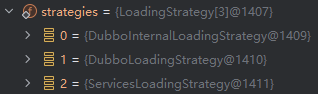
上面的代码会遍历所有加载策略,因此我们需要看看到底有哪些加载策略,加载策略数组strategies的初始化会在ExtensionLoader 类的静态代码块中完成,以下是相关代码:
1 2 3 4 5 6 7 private static volatile LoadingStrategy[] strategies = loadLoadingStrategies();private static LoadingStrategy[] loadLoadingStrategies() { return (LoadingStrategy[])StreamSupport.stream(ServiceLoader.load(LoadingStrategy.class).spliterator(), false ).sorted().toArray((x$0 ) -> { return new LoadingStrategy [x$0 ]; }); }
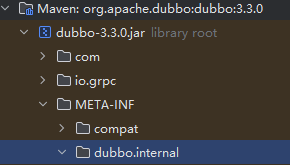
初始化完成后,可以发现strategies数组中的元素其实就是我们刚刚分析的那三类,因此就会从 META - INF/dubbo/internal、META - INF/dubbo、META - INF/services这三个目录下查找,如下图所示:
说回正题,loadDirectory在经过一系列调用链后会调用loadClass方法,关键代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 private void loadClass (ClassLoader classLoader, Map<String, Class<?>> extensionClasses, URL resourceURL, Class<?> clazz, String name, boolean overridden) { boolean isActive = this .loadClassIfActive(classLoader, clazz); if (isActive) { if (clazz.isAnnotationPresent(Adaptive.class)) { this .cacheAdaptiveClass(clazz, overridden); } else if (this .isWrapperClass(clazz)) { this .cacheWrapperClass(clazz); } else { if (StringUtils.isEmpty(name)) { name = this .findAnnotationName(clazz); if (name.length() == 0 ) { throw new IllegalStateException ("No such extension name for the class " + clazz.getName() + " in the config " + resourceURL); } } String[] names = NAME_SEPARATOR.split(name); if (ArrayUtils.isNotEmpty(names)) { this .cacheActivateClass(clazz, names[0 ]); String[] var9 = names; int var10 = names.length; for (int var11 = 0 ; var11 < var10; ++var11) { String n = var9[var11]; this .cacheName(clazz, n); this .saveInExtensionClass(extensionClasses, clazz, n, overridden); } } } } } private void saveInExtensionClass (Map<String, Class<?>> extensionClasses, Class<?> clazz, String name, boolean overridden) { Class<?> c = (Class)extensionClasses.get(name); if (c != null && !overridden) { if (c != clazz) { this .unacceptableExceptions.add(name); String duplicateMsg = "Duplicate extension " + this .type.getName() + " name " + name + " on " + c.getName() + " and " + clazz.getName(); logger.error("0-15" , "" , "" , duplicateMsg); throw new IllegalStateException (duplicateMsg); } } else { extensionClasses.put(name, clazz); } }
总的来说,loadClass其实就是根据不同的类操作不同的缓存,最终得到一个类名到class的映射。共有三种情况:Adaptive 、WrapperClass 和普通类,普通类又将Activate记录了一下。对于普通类来说,整个SPI过程就是这样。
@Adaptive注解
@Adaptive 注解的主要作用是实现自适应扩展,即在运行时根据不同的条件动态地选择合适的扩展实现类。在 Dubbo 的 SPI 机制里,可能存在多个扩展实现类,而 @Adaptive 注解可以让系统在运行时根据具体的参数、配置或者上下文信息,自动决定使用哪个扩展实现类,避免了在代码中硬编码扩展实现类的名称。实现原理主要基于动态字节码生成和 URL 参数解析。
在 Dubbo 中,很多拓展都是通过 SPI 机制进行加载的,比如 Protocol、Cluster、LoadBalance 等。有时,有些拓展并不想在框架启动阶段被加载,而是希望在拓展方法被调用时,根据运行时参数进行加载。这听起来有些矛盾。拓展未被加载,那么拓展方法就无法被调用(静态方法除外)。拓展方法未被调用,拓展就无法被加载。对于这个矛盾的问题,Dubbo 通过自适应拓展机制很好的解决了。自适应拓展机制的实现逻辑比较复杂,首先 Dubbo 会为拓展接口生成具有代理功能的代码。然后通过 javassist 或 jdk 编译这段代码,得到 Class 类,最后再通过反射创建代理类。
加载自适应扩展类的入口是 ExtensionLoader 的 getAdaptiveExtension 方法。依然是经典的双检锁+缓存:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public T getAdaptiveExtension () { Object instance = cachedAdaptiveInstance.get(); if (instance == null ) { if (createAdaptiveInstanceError != null ) { throw new IllegalStateException ("Failed to create adaptive instance: " + createAdaptiveInstanceError.toString(), createAdaptiveInstanceError); } synchronized (cachedAdaptiveInstance) { instance = cachedAdaptiveInstance.get(); if (instance == null ) { try { instance = createAdaptiveExtension(); cachedAdaptiveInstance.set(instance); } catch (Throwable t) { createAdaptiveInstanceError = t; throw new IllegalStateException ("Failed to create adaptive instance: " + t.toString(), t); } } } } return (T) instance; }
下面,我们看一下被调用的 createAdaptiveExtension 方法的代码。
1 2 3 4 5 6 7 8 private T createAdaptiveExtension () { try { return injectExtension((T) getAdaptiveExtensionClass().newInstance()); } catch (Exception e) { throw new IllegalStateException ("Can not create adaptive extension ..." ); } }
createAdaptiveExtension 方法的代码比较少,但却包含了三个逻辑,分别如下:
调用 getAdaptiveExtensionClass 方法获取自适应拓展 Class 对象
通过反射进行实例化
调用 injectExtension 方法向拓展实例中注入依赖
前两个逻辑比较好理解,第三个逻辑用于向自适应拓展对象中注入依赖。这个逻辑看似多余,但有存在的必要,这里简单说明一下。前面说过,Dubbo 中有两种类型的自适应拓展,一种是手工编码的,一种是自动生成的。手工编码的自适应拓展中可能存在着一些依赖,而自动生成的 Adaptive 拓展则不会依赖其他类。这里调用 injectExtension 方法的目的是为手工编码的自适应拓展注入依赖。接下来,分析 getAdaptiveExtensionClass 方法的逻辑。
1 2 3 4 5 6 7 8 9 10 private Class<?> getAdaptiveExtensionClass() { getExtensionClasses(); if (cachedAdaptiveClass != null ) { return cachedAdaptiveClass; } return cachedAdaptiveClass = createAdaptiveExtensionClass(); }
getAdaptiveExtensionClass 方法同样包含了三个逻辑,如下:
调用 getExtensionClasses 获取所有的拓展类
检查缓存,若缓存不为空,则返回缓存
若缓存为空,则调用 createAdaptiveExtensionClass 创建自适应拓展类
这三个逻辑看起来平淡无奇,似乎没有多讲的必要。但是这些平淡无奇的代码中隐藏了着一些细节,需要说明一下。首先从第一个逻辑说起,getExtensionClasses 这个方法用于获取某个接口的所有实现类。比如该方法可以获取 Protocol 接口的 DubboProtocol、HttpProtocol、InjvmProtocol 等实现类。在获取实现类的过程中,如果某个实现类被 Adaptive 注解修饰了,那么该类就会被赋值给 cachedAdaptiveClass 变量。此时,上面步骤中的第二步条件成立(缓存不为空),直接返回 cachedAdaptiveClass 即可。如果所有的实现类均未被 Adaptive 注解修饰,那么执行第三步逻辑,创建自适应拓展类。相关代码如下:
1 2 3 4 5 6 7 8 9 private Class<?> createAdaptiveExtensionClass() { String code = new AdaptiveClassCodeGenerator (type, cachedDefaultName).generate(); ClassLoader classLoader = findClassLoader(); org.apache.dubbo.common.compiler.Compiler compiler = ExtensionLoader.getExtensionLoader(org.apache.dubbo.common.compiler.Compiler.class).getAdaptiveExtension(); return compiler.compile(code, classLoader); }
createAdaptiveExtensionClass 方法用于生成自适应拓展类,该方法首先会生成自适应拓展类的源码,然后通过 Compiler 实例(Dubbo 默认使用 javassist 作为编译器)编译源码,得到代理类 Class 实例。接下来,把重点放在代理类代码生成的逻辑上。
自适应拓展类代码生成
AdaptiveClassCodeGenerator#generate 方法生成扩展类代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public String generate () { if (!hasAdaptiveMethod()) { throw new IllegalStateException ("No adaptive method exist on extension " + type.getName() + ", refuse to create the adaptive class!" ); } StringBuilder code = new StringBuilder (); code.append(generatePackageInfo()); code.append(generateImports()); code.append(generateClassDeclaration()); Method[] methods = type.getMethods(); for (Method method : methods) { code.append(generateMethod(method)); } code.append("}" ); if (logger.isDebugEnabled()) { logger.debug(code.toString()); } return code.toString(); }
生成方法
上面代码中,生成方法的逻辑是最关键的,我们详细分析下。
1 2 3 4 5 6 7 8 9 private String generateMethod (Method method) { String methodReturnType = method.getReturnType().getCanonicalName(); String methodName = method.getName(); String methodContent = generateMethodContent(method); String methodArgs = generateMethodArguments(method); String methodThrows = generateMethodThrows(method); return String.format(CODE_METHOD_DECLARATION, methodReturnType, methodName, methodArgs, methodThrows, methodContent); }
generateMethodContent 分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 private String generateMethodContent (Method method) { Adaptive adaptiveAnnotation = method.getAnnotation(Adaptive.class); StringBuilder code = new StringBuilder (512 ); if (adaptiveAnnotation == null ) { return generateUnsupported(method); } else { int urlTypeIndex = getUrlTypeIndex(method); if (urlTypeIndex != -1 ) { code.append(generateUrlNullCheck(urlTypeIndex)); } else { code.append(generateUrlAssignmentIndirectly(method)); } String[] value = getMethodAdaptiveValue(adaptiveAnnotation); boolean hasInvocation = hasInvocationArgument(method); code.append(generateInvocationArgumentNullCheck(method)); code.append(generateExtNameAssignment(value, hasInvocation)); code.append(generateExtNameNullCheck(value)); code.append(generateExtensionAssignment()); code.append(generateReturnAndInvocation(method)); } return code.toString(); }
上面那段逻辑主要做了如下几件事: 1.检查方法上是否 Adaptive 注解修饰 2.为方法生成代码的时候,参数列表上要有 URL(或参数对象中有 URL) 3.使用 ExtensionLoader.getExtension 获取扩展 4.执行对应的方法
WrapperClass-AOP机制
Dubbo AOP 机制采用 wrapper 设计模式实现,要成为一个 AOP wrapper 类,必须同时满足以下几个条件:
wrapper 类必须实现 SPI 接口,如以下示例中的;
构造器 constructor 必须包含一个相同的 SPI 参数;
wrapper 类必须和普通的 SPI 实现一样写入配置文件,如以下示例:
1 2 3 4 5 6 7 8 9 public class QosProtocolWrapper implements Protocol , ScopeModelAware { private final Protocol protocol; public QosProtocolWrapper (Protocol protocol) { if (protocol == null ) { throw new IllegalArgumentException ("protocol == null" ); } this .protocol = protocol; } }
配置文件 resources/META-INF/dubbo/internal/org.apache.dubbo.rpc.Protocol:
1 qos =org.apache.dubbo.qos.protocol.QosProtocolWrapper
只要满足上述三个条件,扩展类就会被判定为包装类被包在实例外面,进而起到AOP拦截的效果。
injectExtension-IOC机制
Dubbo IOC 通过 setter 方法注入依赖。Dubbo 首先会通过反射获取到实例的所有方法,然后再遍历方法列表,检测方法名是否是set方法。如果是,说明当前是一个需要注入的依赖对象,Dubbo会通过 ObjectFactory 获取依赖对象,然后通过反射调用 setter 方法将依赖设置到目标对象中。整个过程对应的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 private T injectExtension (T instance) { if (objectFactory == null ) { return instance; } try { for (Method method : instance.getClass().getMethods()) { if (!isSetter(method)) { continue ; } if (method.getAnnotation(DisableInject.class) != null ) { continue ; } if (method.getDeclaringClass() == ScopeModelAware.class) { continue ; } if (instance instanceof ScopeModelAware || instance instanceof ExtensionAccessorAware) { if (ignoredInjectMethodsDesc.contains(ReflectUtils.getDesc(method))) { continue ; } } Class<?> pt = method.getParameterTypes()[0 ]; if (ReflectUtils.isPrimitives(pt)) { continue ; } try { String property = getSetterProperty(method); Object object = objectFactory.getExtension(pt, property); if (object != null ) { method.invoke(instance, object); } } catch (Exception e) { logger.error("Failed to inject via method " + method.getName() + " of interface " + type.getName() + ": " + e.getMessage(), e); } } } catch (Exception e) { logger.error(e.getMessage(), e); } return instance; }
@Activate注解
Activate注解用来控制SPI扩展在什么场景下加载生效,有三个参数,group 表示修饰在哪个端(provider 还是 consumer),value = "xxx"表示在 URL参数中出现xxx才会被激活,order 表示实现类的顺序。
参考
扩展点开发指南 | Apache Dubbo
《Dubbo系列》-Dubbo SPI机制
Spring SPI
文件必须放在META-INF/目录底下,文件名为spring.factories。
文件内容为键值对,键为接口的全限定名,值为接口实现的全限定名,多个实现逗号分隔。
Springboot3.0之后可在 META-INF/spring/目录下的org.springframework.boot.autoconfigure.AutoConfiguration.imports 文件中,内容为接口实现全限定名。
如果要扩展某个接口的话,只需要在自己的项目(spring boot)里新建一个META-INF/spring.factories文件,仅添加需要的配置即可。
Spring SPI 不同的接口扩展都写在一个文件里,不像Java SPI 不同接口需要创建不同文件。 Spring SPI 提供了获取类限定名方法。可以获取到类限定名之后就可以将这些类注入到Spring容器中,用Spring容器加载这些Bean,而不仅仅是通过反射。但是Spring SPI 一样没有实现按需加载。
特性
JDK SPI
DUBBO SPI
Spring SPI
文件方式
每个扩展点单独一个文件
每个扩展点单独一个文件
所有的扩展点在一个文件
按需获取某个实现
不支持,只能按顺序获取所有实现
有“别名”的概念,可以通过名称获取扩展点的某个固定实现,配合Dubbo SPI的注解很方便
不支持,只能按顺序获取所有实现。但由于Spring Boot ClassLoader会优先加载用户代码中的文件,所以可以保证用户自定义的spring.factories文件在第一个,通过获取第一个factory的方式就可以固定获取自定义的扩展
其他
无
支持Dubbo内部的依赖注入,通过目录来区分Dubbo内置SPI和外部SPI,优先加载内部,保证内部的优先级最高
无
__END__